Taikydami faktorinę analizę, ieškome stebimų kintamųjų panašumų. Žinoma, jeigu kintamieji nekoreliuoti, tai ir panašumų nėra. Todėl nekoreliuotiems kintamiesiems faktorinė analizė neturi prasmės. Vadinasi, visų pirma trime įsitikinti, ar stebimi kintamieji tarpusavyje koreliuoja.
Pradiniai faktorinės analizės duomenys – stebėjimų koreliacijų (arba kovariacijų) matrica. Iš jos pavidalo matyti, kurie kintamieji nepriklausomi nuo likusiųjų. Šie kintamieji negrupuojami, t.y faktiškai sudaro atskirus faktoriu. Todėl juos iš faktorinės analizės pradinių kintamųjų sąrašo verta pašalinti.
Jeigu taikant Bartleto sferiškumo kriterijų p-reikšmė  , tai turimiems duomenims faktorinė analizė netaikytina; čia
, tai turimiems duomenims faktorinė analizė netaikytina; čia  – pasirinktasis reikšmingumo lygmuo.
– pasirinktasis reikšmingumo lygmuo.
Ar kintamieji (kartu ir duomenys) tinka faktorinei analizei, įvertina Kaizerio-Mejerio-Olkino (KMO) matas. Šis matas – empirnių koreliacijos koeficientų didumų ir dalinių koreliacijos koeficientų didumų palyginamasis indeksas. Jis skaičiuojams pagal formulę:

čia  – kintamųjų
– kintamųjų  ir
ir 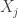 koreliacijos koeficientas,
koreliacijos koeficientas,  –
–  ir dalinės koreliacijos koeficientas. Jei KMO mato reikšmė maža, tai nakrinėjamų kintamųjų faktorinė analizė nerezultatyvi. Iš tiesų maža KMO mato reiikšmė rodo, kad kintmųjų porų koreliacija nėra paaiškinama kitais kintamaisiais.
ir dalinės koreliacijos koeficientas. Jei KMO mato reikšmė maža, tai nakrinėjamų kintamųjų faktorinė analizė nerezultatyvi. Iš tiesų maža KMO mato reiikšmė rodo, kad kintmųjų porų koreliacija nėra paaiškinama kitais kintamaisiais.
Naudojama tokia KMO reikšmių gradacija iš akies: 0,9<KMO – faktorinė analizė puikiai tinka,  – gerai tinka,
– gerai tinka,  – tinka patenkinama,
– tinka patenkinama,  – tinka pakenčiamai,
– tinka pakenčiamai,  – tinka blogai, KMO<0,5 – faktorinė analizė nepriimtina.
– tinka blogai, KMO<0,5 – faktorinė analizė nepriimtina.
Kiekvieno kintamojo stebėjimų tinkamumo matą galima apskaičiuoti pagal formulę:

Kintamuosius, kuriems  rekšmės mažos, verta iš faktorinės analizės pašalinti.
rekšmės mažos, verta iš faktorinės analizės pašalinti.
PVZ. Reklamos agentūra, norėdama sužinoti, kokiom naujojo produkto “Auksinė žuvelė“ charakteristikoms pirkėjas teikia priklausomybę, atliko tyrimą. 50 pirkėjų pagal 7 balų skalę turėjo įvertinti tokias charakteristikas: skonį (SKN), armotą (ARM), energetinę vertę (ENV), gerą kainą (KAI), tinkamumą užkandai (UŽK). Domenų koreliacijų matrica pateikta lentelėje.
|
SKN |
ARM |
ENV |
KAI |
UŽK |
| SKN |
1 |
0,46 |
0,14 |
0,07 |
0,18 |
| ARM |
0,46 |
1 |
0,12 |
0,19 |
0,16 |
| ENV |
0,14 |
0,12 |
1 |
0,25 |
0,44 |
| KAI |
0,07 |
0,19 |
0,25 |
1 |
0,39 |
| UŽK |
0,18 |
0,16 |
0,44 |
0,39 |
1 |
Apskaičiavę KMO, gauname: KMO = 0,606 . Vadinasi duomenų aibė pakenčiamai tinka faktorinei analizei.
Taigi, pirmiausiai reikia patikrinti, ar tinka duomenys faktorinei analizei, o poto jau taikyti pačią faktorinę analizę ir ieškoti bendrų faktorių, kurie paaiškintų tarpusavio koreliaciją.
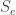

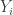



 , t.y. ieškome 90% apytiklio prognozavimo intervalo. Reikšmė t gaunama iš Stjudento pasiskirstymo lentelių, esant 2 laisvės laipsniams atitinkamame stulpelyje. Ji lygi 2,90, taigi viršutinė intervalo riba:
, t.y. ieškome 90% apytiklio prognozavimo intervalo. Reikšmė t gaunama iš Stjudento pasiskirstymo lentelių, esant 2 laisvės laipsniams atitinkamame stulpelyje. Ji lygi 2,90, taigi viršutinė intervalo riba: tiesinės daugialypės regresijos modelis atrodo taip:
tiesinės daugialypės regresijos modelis atrodo taip: (1)
(1) yra atsitiktinė paklaida. Iš pradžių išsiaiškinsime, kodėl dvireikšmiam kintamajam prognozuoti netinka tiesinė regresija. Visų pirma, netenkinamos tiesinės regresijos prielaidos. Iš tikrųjų,
yra atsitiktinė paklaida. Iš pradžių išsiaiškinsime, kodėl dvireikšmiam kintamajam prognozuoti netinka tiesinė regresija. Visų pirma, netenkinamos tiesinės regresijos prielaidos. Iš tikrųjų,  taip pat gali įgyti tik dvi reikšmes (netenkinama normalumo prielaida). Žinome, kad tiesinėje regresijoje prognozuojamas priklausomo kintamojo vidurkis. Kadangi E
taip pat gali įgyti tik dvi reikšmes (netenkinama normalumo prielaida). Žinome, kad tiesinėje regresijoje prognozuojamas priklausomo kintamojo vidurkis. Kadangi E , tai prognozuotume tikimybę, su kuria
, tai prognozuotume tikimybę, su kuria 



 vadinamas galimybe (galimybės įvertinimu) įvykti įvykiui
vadinamas galimybe (galimybės įvertinimu) įvykti įvykiui 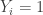 . Įvykio Y=1 galimybė įvykti yra didesnė už 1 tada ir tik tada, kai P(Y=1)>P(Y=0).
. Įvykio Y=1 galimybė įvykti yra didesnė už 1 tada ir tik tada, kai P(Y=1)>P(Y=0). nuo kintamųjų reikšmių
nuo kintamųjų reikšmių  priklauso tiesiškai. Be to, jis gali įgyti reikšmes iš intervalo
priklauso tiesiškai. Be to, jis gali įgyti reikšmes iš intervalo  Todėl šiuo atveju taikant (1) modelį nekyla problemos, kad prognozuojamoji reikšmė nepateks į leistinų reikšmių intervalą. Kai
Todėl šiuo atveju taikant (1) modelį nekyla problemos, kad prognozuojamoji reikšmė nepateks į leistinų reikšmių intervalą. Kai  įgyja labai mažas reikšmes, tai
įgyja labai mažas reikšmes, tai  tai
tai 
 , tai
, tai  t.y. galime sakyti, kad galimybė
t.y. galime sakyti, kad galimybė  nebūtinai turi būti normalieji. Nereikalaujama normaliai pasiskirsčiusių paklaidų.
nebūtinai turi būti normalieji. Nereikalaujama normaliai pasiskirsčiusių paklaidų. , neišsiversime be kombinatorikos formulių.
, neišsiversime be kombinatorikos formulių.


 Kadangi mus domina tik tie respndentai, kurie keitė nuomonę, tai skaičiuojant statistiką tik jų duomenys ir naudojami. Užrašoma tokia statistika:
Kadangi mus domina tik tie respndentai, kurie keitė nuomonę, tai skaičiuojant statistiką tik jų duomenys ir naudojami. Užrašoma tokia statistika:
 skirstinio su (2-1)(2-1)=1 laisvės laipsniu
skirstinio su (2-1)(2-1)=1 laisvės laipsniu 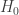 teigia, kad simpatizuojančių kandidatams L ir V žiūrovų dalys populiacijoje liko nepakitusios. Alternatyva
teigia, kad simpatizuojančių kandidatams L ir V žiūrovų dalys populiacijoje liko nepakitusios. Alternatyva 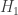 teigia, kad dalis remiančių vieną iš kandidatų po debatų padidėjo (o remiančių kitą kandidatą, sumažėjo). Taigi
teigia, kad dalis remiančių vieną iš kandidatų po debatų padidėjo (o remiančių kitą kandidatą, sumažėjo). Taigi

 yra dalis žiūrovų, kurie prieš TV debatus ruošėsi balsuoti už kandidatą L, o po TV debatų – už V;
yra dalis žiūrovų, kurie prieš TV debatus ruošėsi balsuoti už kandidatą L, o po TV debatų – už V;  – dalis žiūrovų, kurie prieš TV debatus ruošėsi balsuoti už kandidatą V, o po TV debatų – už L.
– dalis žiūrovų, kurie prieš TV debatus ruošėsi balsuoti už kandidatą V, o po TV debatų – už L.
 Tuomet, iš lentelių randame
Tuomet, iš lentelių randame  Kadangi, 3,49<6,635, tai nulinę hipotezę atmesti nėra pagrindo. Vadinasi, TV debatai kandidatų rėmėjų skaičiaus pokyčiams įtakos neturėjo.
Kadangi, 3,49<6,635, tai nulinę hipotezę atmesti nėra pagrindo. Vadinasi, TV debatai kandidatų rėmėjų skaičiaus pokyčiams įtakos neturėjo. . SKaičiavimams patogiau naudoti formulę:
. SKaičiavimams patogiau naudoti formulę: .
. ,
, ;
; .
.




 .
. .
. .
. , tai a
, tai a  .
. E|X| .
E|X| . ; ir 0, kitu atveju.
; ir 0, kitu atveju. = 2,5 .
= 2,5 . .
. (X,Y) =
(X,Y) =  =
=  .
.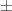 1 tada ir tik tada, kai egzistuoja konstantos a
1 tada ir tik tada, kai egzistuoja konstantos a 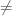 0 ir b tokios, kad Y = aX + b .
0 ir b tokios, kad Y = aX + b . yra nepriklausomi, todėl cov (X ,Y) = E
yra nepriklausomi, todėl cov (X ,Y) = E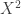 Z-EXEY = E
Z-EXEY = E = 24 ,
= 24 ,  = 29.
= 29. = 6 ,
= 6 ,  = 7 . Iš lentelių randame kritinę reikšmę, atitinkančią
= 7 . Iš lentelių randame kritinę reikšmę, atitinkančią 